
Unsupervised learning helps to find a hidden jewel in data by grouping similar things together. Data have no target attribute. The algorithm takes training examples as the set of attributes/features alone. In this post, I have summarised my whole upcoming book “Unsupervised Learning – The Unlabelled Data Treasure” on one page. This one-page guide is to know everything about unsupervised learning on a high level. For details wait for the book release in June-2019.
Unsupervised Learning Demystified
Unsupervised learning is classified as one of the three categories of machine learning, alongside Supervised Machine Learning, and Reinforcement Learning. Specifically, it falls under the domain of Unsupervised Machine Learning (UML). The predominant technique utilized in the Unified Modeling Language (UML) is cluster analysis. Cluster analysis is employed as a means of discovering concealed patterns or categories within data beyond conventional analytical methods. The present study utilized an algorithm to extract meaningful insights from unlabeled input data sets. In brief, the Unified Modeling Language (UML) constitutes a standardized modeling notation used in software engineering for the purpose of visualizing, specifying, constructing, and documenting the artifacts of software systems.- A technique with the idea to explore hidden gems/patterns.
- To find some intrinsic structure in data.
- That something can’t be seen with naked eye requires magnifier (UML)
In UML systems are not trained by feeding it with the intended answers unlike what we do in supervised learning. Rather we just allow algorithms to infer patterns from a dataset without reference to known, or labelled outcomes. There are mainly 2 ways we achieve unsupervised learning goals
- Clustering – Partitions data into distinct clusters based on distance to the centroid of a cluster
- Association – The association rules are used to discover interesting patterns.
UML can’t be applied to a regression or a classification problem as there is no idea what the values for the output data might be. Unsupervised learning algorithms get trained completely differently compared to supervised learning. Instead, algorithms here work as secret agents (yeah maybe 007 styles) for discovering the underlying structure of the data.
Clustering The Data
Clustering allows grouping of data points i.e. automatically split the dataset into groups according to similarity. Algorithms in this technique are based on one principle which is similarity/dissimilarity.
When clustering algorithm is used it classify the data points in groups with similar properties & features and underline them as a common reason to group. So each group has data points with similarity while intra-groups feature and properties are dissimilar to each other.
Because of the reason above it often overestimates the similarity between groups. Overestimates brings poor quality thus bad results. While clustering may work well for customer segmentation but do poorly on targeting.
Common Clustering Algorithms
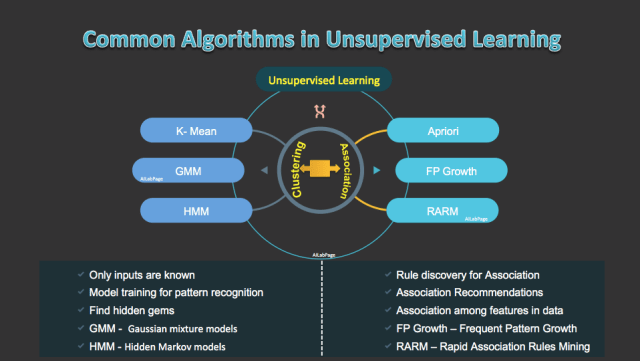
- K-Means Clustering: The most common and well know clustering algorithm. Super simple to understand, code and implement. It starts from the centre points of vectors of the same length. It’s pretty fast as well.
- Mean-Shift Clustering: This algorithm works with baby step strategy. It’s a sliding-window-based algorithm for finding its dense areas of data points. It gives freedom from selecting the number of clusters as it automatically discovers.
- DBSCAN Clustering: It’s a density-based spatial clustering of applications with noise algorithm. Based on density and starts with an arbitrary data point that has not been visited. It does not need a pre-set number of clusters.
- Expectation Maximization: This clustering method uses Gaussian Mixture Models (GMM). To distribute GMM parameters for each cluster randomly it starts by selecting the number of clusters. GMMs are a lot more flexible in terms of cluster covariance and can have multiple clusters per data point.
- Agglomerative Hierarchical Clustering: Cluster tree is built with the multilevel hierarchy of clusters. No assumptions on the number of clusters
- Agglomerative – In this technique, its start with the points as each cluster as it moves forward; at each step, merge the closest pair of clusters until only one cluster left.
- Divisive – Here its start with one, all-inclusive cluster. At each step, split a cluster until each cluster has a point.
Association Mining In Data
In contrast with sequence mining, association rule learning typically does not consider the order of items either within a transaction or across transactions. Association rules mining is another key unsupervised data mining method, after clustering, that finds interesting associations (relationships, dependencies) in large sets of data items.
The association rule mining is used in unsupervised scenarios to discover interesting patterns. It also gets used in supervised learning as well. It identifies sets of items that often occur together. Data mining transform data into useful information.
E-commerce companies used this commonly and on an almost everyday basis. It is used for the shopping cart or basket analysis. It is very helpful to analysts to discover bundle goods often purchased at the same time and to develop more effective marketing strategies.
- Apriori Algorithm
- Frequent Pattern (FP) Growth Algorithm
- Rapid Association Rule Mining (RARM)
- ECLAT Algorithm
- Associated Sensor Pattern Mining of Data Stream (ASPMS) – For greater needs of frequent pattern mining algorithms.
Association is just a frequently appeared patterns over large transactional databases. AILabPage can suggest a comparative study of the above-mentioned algorithms for advanced learners in data mining.
An Angle for Unlabelled Data & Secret Labels
Unsupervised learning can be a challenging goal in itself. The training data consists of a set of input vectors x without any corresponding target values; hence known as learning/working without a supervisor.
The system does self-discovery of patterns, regularities and features etc. from the input data and relations for the input data over output data. Discovering similarities and dissimilarities to forms clusters i.e. self-discovery is the main target here.
Examples given to the learner are unlabelled, there is no error or reward signal to check a potential solution. Since no labels are given to the learning algorithm, leaving it on its own to find structure in its input. This distinguishes unsupervised learning from supervised learning and reinforcement learning.
- Pros
- It can detect what human eyes can not understand
- The potential of hidden patterns can be very powerful for the business or even detect extremely amazing facts, fraud detection etc.
- Output can decide the unexplored territories and new ventures for businesses. Exploratory analytics can be applied to understand the financial, business and working drivers behind what happened.
- Cons
- As seen in the above explanation unsupervised learning is harder as compared to supervised learning.
- It can be a costly affair, as we might need external expert look at the results for some time.
- Usefulness of the results; are of any value or not is difficult to confirm since no answer labels are available.
Guarantee to no guarantee
What is guaranteed in unsupervised learning is; there is no guarantee or assurance that after so much of efforts and hard work of massaging the data we will find anything inspiring or something useful in data.
Since outcomes are known thus there is no way to decide accuracy of it. This makes supervised machine learning more applicable to real-world problems. The best time to use unsupervised machine learning is when you don’t have data on desired outcomes, like determining a target market for an entirely new product that your business has never sold before.
Why is Unsupervised Machine Learning important?
One of the biggest advantages of unsupervised machine learning methods is reusability for other learning methods. The patterns uncovering & detection with unsupervised machine learning methods come in handy when implementing supervised machine learning.
- Anomaly Detection- This is the key feature for automatic discovery of unusual data points in a given dataset. As shown in the above picture the outlier can pinpoint fraudulent transactions/activities. Discovering faulty pieces of hardware or identifying an outlier caused by a human error during data entry are also seen here.
- Latent Variable Models- The data preprocessing happens in every business every day and most of the time too much similar data with the same features. Latent variable modelling helps in performing dimensional reduction i.e. reducing the number of features in the dataset or decomposing the dataset into multiple components.
Some of the Use Cases
Unsupervised learning is used to find anomalies in data or cluster data items to groups that humans can’t assume themselves. Since output variables are unspecified here so algorithms look for structures in the data to describe and hidden distribution or structure of data. Some of the examples here are.
- Customer segmentation in different groups for specific interventions
- Product Targeting
- Market Categorisation
- Recommendation Engines
Points to Note:
All credits if any remains on the original contributor only. We have covered Unsupervised machine learning in this post, where we find hidden gems from unlabelled historical data. The last post was on Supervised Machine Learning. In the next upcoming post will talk about Reinforcement machine learning.
Books & Other Material Referred
- Open Internet & AILabPage (group of self-taught engineers) members hands-on lab work.
- Book “Artificial Intelligence: A Modern Approach”
Feedback & Further Question
Do you have any questions about Deep Learning or Machine Learning? Leave a comment or ask your question via email. Will try my best to answer it.

Conclusion – Collecting and labelling a large set of sample patterns can be very expensive. How this type of learning helps business to see some potentials which are usually hidden normally.
The goal in such unsupervised learning problems may be to discover groups of similar examples within the data, where it is called clustering, or to decide how the data is distributed in the space, known as density estimation.

[…] Unsupervised Machine Learning – Magnify hidden patterns and trends […]
[…] Learning (RL) – A more general form of machine learning than supervised learning or unsupervised learning. It learn from interaction with environment to achieve a goal or simply learns from reward and […]
[…] Unsupervised Learning – Everything you need to know (Basics) […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure or hidden patterns for useful information in inputs. […]
Interesting post. I Have Been wondering about this issue, so thanks for posting. Pretty cool post.It ‘s really very nice and Useful post.Thanks
professional course
Hi I have read a lot from this blog thank you for sharing this information. We provide all the essential courses for professionals like Data Science Course In Jaipur , Full stack Developer, data structures courses, System design course , Python, AI and Machine Learning, Tableau, etc. for more information log in to our website https://skillslash.com/system-design-course