Supervised Machine Learning: This is our first post in this sub-series “Machine Learning Type” under the master series “Machine Learning Explained“. We will only talk about supervised machine learning in detail here. Machine learning algorithms “learn” from the observations. When exposed to more observations, the algorithm improves its predictive performance.
Supervised Machine Learning is a type of system in which both input and desired output data are provided.
Machine Learning for Businesses
In the realm of marketing, the utilization of supervised learning is becoming increasingly beneficial. Can we estimate the increase in revenue through increased investment in digital advertising? Similarly, can we make minor forecasts for the stock markets, such as predicting their direction the following day?

Machine learning techniques are accelerating almost on a daily basis with intentions to bring good values to the businesses of today. It is revolutionizing the way we do our business and what should be done to improve upon it. On a high level, we have three main types of machine learning: supervised, unsupervised, and reinforcement learning. Since this post is limited to supervised learning and what it is doing in business, I will stick to it for now.
Supervised Machine Learning -SML
Let’s understand a bit about SML and find answers around what it does, how it does it, and what it can do for our real-life business. Supervised learning through historical data sets is able to hunt for correct answers, and the task of the algorithm is to find them in the new data.

How it’s powering our businesses to make sure we survive and get the best out of what we do. Supervised machine learning is
- Is the task of deducing function from labeled training data.
- Making predictions based on evidence in the presence of uncertainty
- Identifying patterns in given data with adaptive algorithms
Machine learning techniques are accelerating on a daily basis with intentions to bring good values to the businesses of today.
Supervised machine learning necessitates partitioning each observation into a couple consisting of an input entity and the corresponding intended output value. In this domain, an algorithmic approach is utilized to derive a formula through the scrutiny of the training data, facilitating the process of mapping novel instances. The training samples consist of a group of exemplars. The educational approach employed in this context employs the subsequent techniques to form predictive

- Regression – To predict the output value using training data.
- Classification – To group the output into a class.
The SML system is characterized by the provision of input and desired output data. In order to establish a foundation for future data processing, the labeling of input and output data is conducted for the purpose of classification. In this paper, the author will provide an empirical analysis and elucidation of techniques utilized in the field of supervised machine learning.
Frequently used Algorithms in Supervised Machine Learning
Supervised learning gives a glimpse of how to solve classification and regression problems. The algorithm is “trained” on a pre-defined set of “training examples”, which then facilitate its ability to reach an accurate conclusion when given new data. It has “labeled” data for creating predictive models by using either type of ML algorithms, as mentioned below. It provides outputs, typically in one of two forms.
- Regression outputs are real-valued numbers that exist in a continuous space.
- Classification outputs, on the other hand, fall into discrete categories.

The algorithms depicted in the aforementioned image shall not be explicated in this discourse, as they have already been defined in a prior publication. Subsequently, our forthcoming articles will endeavor to provide an in-depth analysis of each algorithm, encompassing its definition, application scenarios, and operational modus operandi.
In the interim, it is advisable to concentrate on the concept of supervised learning, where each instance comprises a duo comprising an input entity. Commonly, a vector and the targeted output value.
Supervised Learning Process – SLP
While there are many statistics and machine learning algorithms for supervised learning, most use the same basic workflow for obtaining a predictor model. The accuracy of SLP is determined by the number of correct classifications divided by the total number of test cases. This equation clearly shows that accuracy will be closer to perfection when the difference between “number of correct classifications” and “number of test cases” is minimal.
The process for supervised machine learning is basically a two-step process, as shown below.
- Learning: Learn a model using the training data or train a model using the training data.
- Testing: Test the model using unseen test data to assess the model’s accuracy.

- Prepare data
- Choose an algorithm
- Fit a model
- Choose a validation method
- Examine fit and update until satisfied
- Use the fitted model for predictions
Goals of Supervised Learning
The goal of supervised learning is to approximate the mapping function well. An algorithm is used to learn the mapping function from the input to the output. In other words, when input data (X) comes in, predictions can be made for expected output variables (Y) for that data. Learning stops when the algorithm achieves an acceptable level of performance. This functional mapping takes the general form y = f(x)—specified target output y, provided inputs x—and the ML algorithm will learn the optimal f() by finding patterns in the data.
Y = f(X)
When an algorithm is applied to input variables (X) and an output variable (Y) to learn the mapping function from the input to the output, this tells us that probably supervised machine learning was used here. The processor task is called supervised learning because an algorithm learning from the training data set can be thought of as a supervisor supervising the learning process.
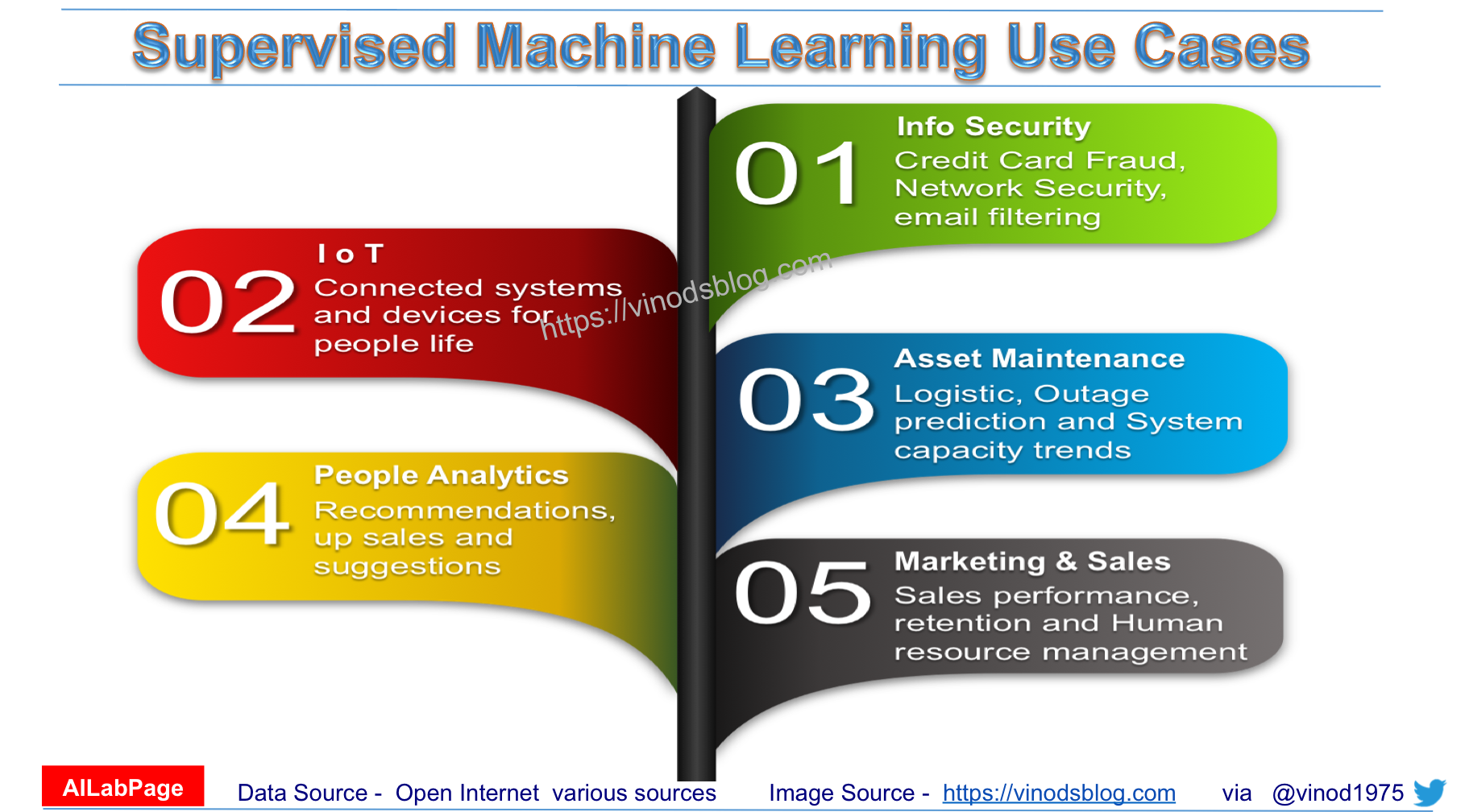
Use cases of Supervised Learning- Real Business
Supervised Learning is as good as low hanging fruit in data science for businesses. The key question when dealing with ML classification is not whether a learning algorithm is superior to others, but under which conditions a particular method can definitely outperform others on a given problem.

A supervised learning model makes predictions based on evidence in the presence of uncertainty. Some of the use cases for supervised learning are depicted in the below picture.
Points to Note:
All credits, if any, remain with the original contributor only. We have covered supervised machine learning, where we make predictions from labeled historical data. In the next post, I will talk about unsupervised machine learning.
Books + Other readings Referred
- Research through open internet, news portals, white papers and imparted knowledge via live conferences & lectures.
- Lab and hands-on experience of @AILabPage (Self-taught learners group) members.
Feedback & Further Question
Do you have any questions about AI, Machine Learning, Data Science or Big Data Analytics? Leave a question in a comment or ask via email. Will try best to answer it.
 Conclusion – Supervised learning, which is one of three types of machine learning. This post is limited to supervised learning in order to explore its details, i.e., what it is doing and can do for businesses as new electricity to power them up. In this blog post, I tried to perform a comparison of different supervised machine learning techniques for classifying FinTech data. This blog post is an attempt to describe the best-known supervised techniques in relative detail but not to claim anything. The aim was to produce a lighter rephrase of supervised learning and a review of the key ideas rather than a simple list of all algorithms in this category.
Conclusion – Supervised learning, which is one of three types of machine learning. This post is limited to supervised learning in order to explore its details, i.e., what it is doing and can do for businesses as new electricity to power them up. In this blog post, I tried to perform a comparison of different supervised machine learning techniques for classifying FinTech data. This blog post is an attempt to describe the best-known supervised techniques in relative detail but not to claim anything. The aim was to produce a lighter rephrase of supervised learning and a review of the key ideas rather than a simple list of all algorithms in this category.

Good Artitmy good sir.
Good Article my good sir, detailed and informative. However for stock markets i liked where you pointed out to say small predictions as the out put is determined by some other aspects like Politics which can not be quantified and or calculated. How then can we still rely on the output keeping in mind such other variables.
This is where error margin comes into play.
Thank you for the post, very informative and well researched information at one place….. Supervised machine learning systems provide the learning algorithms with known quantities to support future judgments.
[…] Our master series for this sub series is “Machine Learning Explained”. First post about Supervised Machine Learning is available […]
[…] Supervised learning: Machine gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] Supervised learning: Supervised learning gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] coming up. This post talks about reinforcement machine learning only. Previous post on Supervised Learning and Unsupervised Learning are […]
[…] Learning; is one of three types of machine learning i.e. Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement Learning. This post is limited to Unsupervised […]
[…] Supervised learning: Machine gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] to give quick glimpse. You can find previous posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] Deep Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] on the original contributor only. You can find our posts on Basic Machine Learning Understanding, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement Learning here. Also we now have post in […]
[…] If supremacy is the basis for popularity then surely Deep Learning is almost there (At least for supervised learning tasks). Deep learning attains the highest rank in terms of accuracy when trained with huge amount […]
[…] learning in this post, where we find hidden gems from unlabelled historical data. Last post was on Supervised Machine Learning. In the next upcoming post will talk about Reinforcement machine […]
[…] it on its own to find structure in its input. This distinguishes unsupervised learning from supervised learning and reinforcement […]
[…] Deep Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] and controls. Data used here is either very less or waiting for the data. Last posts on Supervised Machine Learning and Unsupervised Machine Learning got some decent feedbacks . Our next post will talk […]
[…] Deep Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement […]
[…] Supervised learning: Machine gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] Supervised learning: Machine gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] Deep Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] in this post, where we find hidden gems from unlabelled historical data. The last post was on Supervised Machine Learning. In the next upcoming post will talk about Reinforcement machine […]
[…] in this post, where we find hidden gems from unlabelled historical data. The last post was on Supervised Machine Learning. In the next upcoming post will talk about Deep Reinforcement […]
Learn advanced Data Science & Machine Learning skills from world-renowned IBM faculty. Learn Machine Learning, Deep Learning, NLP, AI, Recommendation Systems, and more. Apply Now. Real-world Case Studies. Access to resource lab. Hands-on Projects.
Apply now: Online Data Science PG Program
[…] Supervised Machine Learning – Insider Scoop for labelled data … […]
[…] Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] Supervised learning: Supervised learning gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output. […]
[…] and controls. Data used here are either very less or waiting for the data. Last posts on Supervised Machine Learning and Unsupervised Machine Learning got some decent feedback. Our next post will talk […]
[…] it on its own to find structure in its input. This distinguishes unsupervised learning from supervised learning and reinforcement […]
[…] Learning only. You can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] Supervised machine learning through historic data sets can hunt for correct answers, and the algorithm’s task is to find them in the new data. It uses labelled data with input features and output labels. The program uses labelled samples to identify correlations between input and output data. Output labels in supervised learning are called the “supervisory signal”. […]
[…] in this post, where we find hidden gems from unlabeled historical data. The last post was on supervised machine learning. In the next post, I will talk about reinforcement machine […]