Unsupervised Learning – It is one of three types of machine learning i.e. Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement Learning. In USL the system engages in a process of self-discovery by identifying patterns, regularities, and features, among other factors. Based on the data entered and the corresponding relationships between the input data and the resulting output data,
This post is limited to Unsupervised Machine Learning to explorer its details.
This is our second post in this sub series “Machine Learning Types”. Our master series for this sub series is “Machine Learning Explained”. First post about Supervised Machine Learning is available here
In Unsupervised Learning; data have no target attribute. In this learning algorithm takes as training examples the set of attributes/features alone.
Unsupervised Machine Learning
The hallmark of unsupervised learning is the absence of a predetermined target attribute in the given dataset. The educational instruction approach is based on the acquisition of traits and attributes that serve as exemplars for instructional purposes.

- A technique with the idea to explore hidden gems / patterns.
- To find some intrinsic structure in data.
- Something cant be seen with naked eye requires magnifier (UML)
In Unsupervised Learning available data have no target attribute. Machine Learning Algorithm takes training examples as the set of attributes/features alone. The purpose of unsupervised learning is to attempt to find natural partitions in the training set.
Types Of Unsupervised Machine Learning
The most common unsupervised learning method is cluster analysis at the same time two general strategies in UML includes:

- Clustering – Partitions data into distinct clusters based on distance to the centroid of a cluster
- Hierarchical Clustering – Cluster tree is build with multilevel hierarchy of clusters. No assumptions on the number of clusters
- Agglomerative – In this technique its start with the points as individual clusters as it move forward; at each step, merge the closest pair of clusters until only one cluster left.
- Divisive – Here its start with one, all-inclusive cluster. At each step, split a cluster until each cluster contains a point.
System does self-discovery of patterns, regularities and features etc. from the input data and relations for the input data over output data. Discovering similarities and dissimilarities to forms clusters i.e. self-discovery is main target here. Since the examples given to the learner are unlabelled, there is no error or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement learning.
Unsupervised learning – Pros & Cons
Since no labels are given to the learning algorithm, leaving it on its own to find structure in its input. Unsupervised learning can be a challenging goal in itself. The training data consists of a set of input vectors x without any corresponding target values; hence known as learning / working without a supervisor.
- Pros
- It can detect what human eyes can not understand
- The potential of hidden patterns can be very powerful for the business or even detect extremely amazing facts, fraud detection etc.
- Output can determine the un explored territories and new ventures for businesses. Exploratory analytics can be applied to understand the financial, business and operational drivers behind what happened.
- Cons
- As seen in above explanation unsupervised learning is harder as compared to supervised learning.
- It can be a costly affair, as we might need external expert look at the results for some time.
- Usefulness of the results; are of any value or not is difficult to confirm since no answer labels are available.
Unsupervised Learning Categories
Unsupervised learning algorithms explore and analyze unlabeled data categories. Categories are utilized to achieve insights, make predictions, and uncover hidden structures in data based on the data’s nature and analysis objectives. Selecting the right category and algorithm for the problem’s characteristics and requirements is called as half won battle.
- Parametric Unsupervised Learning
- Non-parametric Unsupervised Learning
Though in parametric algorithms, despite having not required much data to train, it however does also cause overfitting. It is more common that parametric under fit and non-parametric overfit. Both types of algorithms can over and under fit data though.
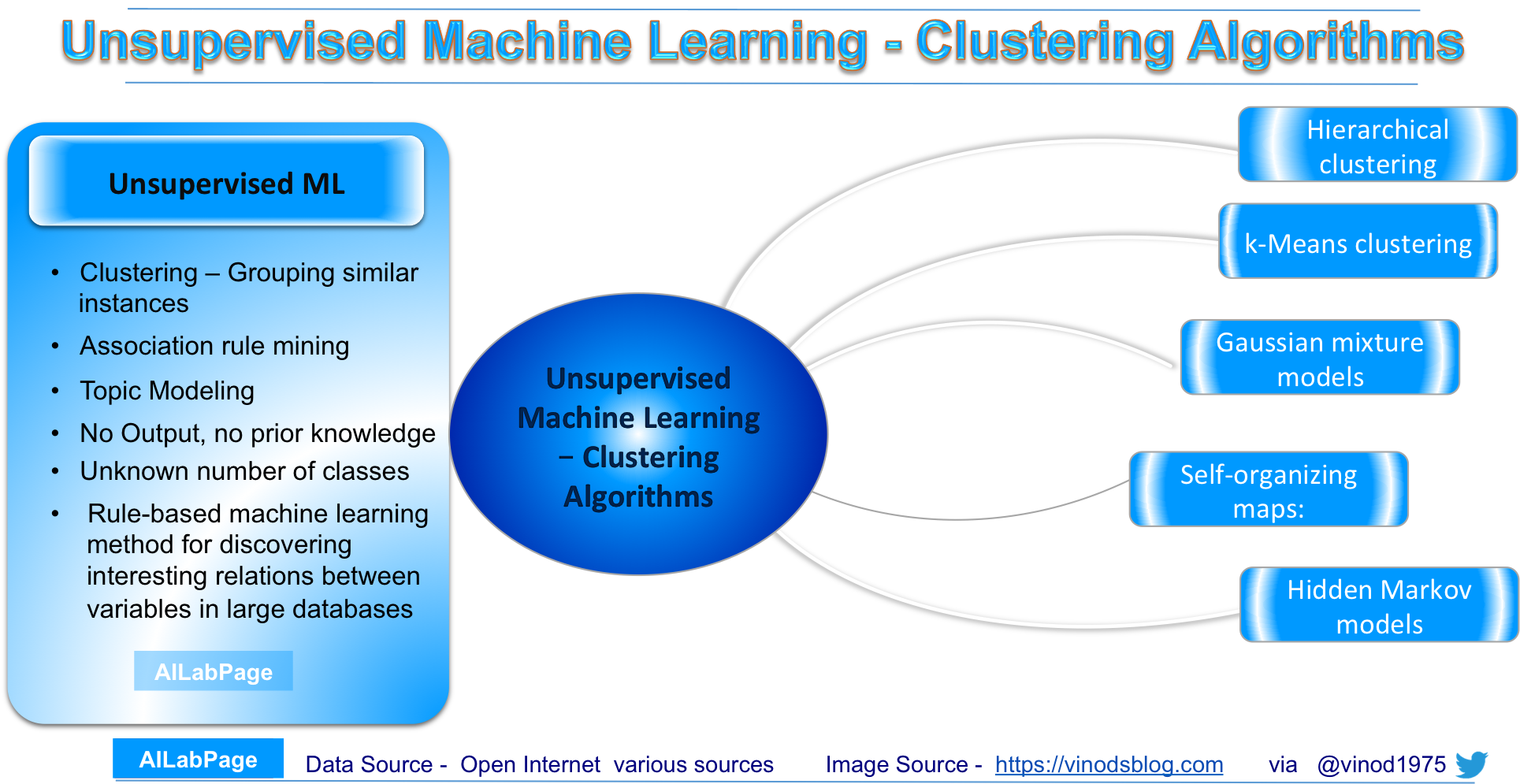
Frequently used algorithms in unsupervised machine learning
Unsupervised machine learning finds hidden patterns within unmarked data. Unsupervised learning includes diverse algorithms for different data types and purposes. This document covers common unsupervised machine learning algorithms. Common algorithms include:
- K-Means clustering: This algorithm partitions data into clusters based on similarity. Aims to minimize the within-cluster sum of squares by iteratively assigning data points to clusters and updating centroids. K-means is common for clustering in many areas.
- Hierarchical clustering: In this technique the algorithm builds a multilevel hierarchy of clusters by creating a cluster tree. Clustering is either merged or gets splitted based on similarity. Forms a dendrogram, cut at various levels for varying cluster quantities. No prior cluster number is needed for hierarchical clustering.
- Gaussian mixture models: Algorithms builds a model in which model clusters a mixture of multivariate normal density components. GMMs assume that data comes from Gaussian mixtures. They estimate Gaussian distribution parameters, like mean and covariance, to represent the data. GMMs commonly cluster, estimate density, and generate data.
- DBSCAN – In this algorithm clusters data points are based on density. Clusters are high-density regions separated by low-density regions. DBSCAN identifies arbitrary-shaped clusters and is robust to noise and outliers.
- Self-Organizing Maps: This one gets super simplified by using neural networks that learn the topology and distribution of the data
- Anomaly Detection – Anomaly detection identifies abnormal data points. Approaches include statistical, clustering, and autoencoder methods for identifying deviations in data.
- Association Rule Mining– It uses logic to find relationships between variables or items in a dataset. These algorithms find common items and generate association rules. Associative rule mining is used in market basket analysis, recommender systems, and sequential pattern mining.
- Hidden Markov models: Simply uses observed data to recover the sequence of states
These are just a few examples of frequently used algorithms in unsupervised machine learning. The choice of algorithm depends on the specific problem, data characteristics, and desired outcomes.
Unsupervised Machine Learning (UML) uses cases for real businesses
UML is used to find anomalies in data or cluster data items to groups that humans can’t assume themselves. Since output variables are unspecified here so algorithms looks for structures in the data to describe and hidden distribution or structure of data.
 Customer segmentation in different groups for specific interventions, product targeting, market categorization and recommendations are few examples here.
Customer segmentation in different groups for specific interventions, product targeting, market categorization and recommendations are few examples here.
The number of cluster seekers can be chosen adaptively as a function of the distance between them and the sample variance of each cluster. The best use for unsupervised is around exploratory analytics to understand the financial, business and operational drivers behind what happened.
Points to Note:
All credits if any remains on the original contributor only. We have covered Unsupervised machine learning in this post, where we find hidden gems from unlabelled historical data. Last post was on Supervised Machine Learning. In the next upcoming post will talk about Reinforcement machine learning.
 Conclusion – Collecting and labelling a large set of sample patterns can be very expensive. How this type of learning helps business to see some potentials which is usually hidden normally. The goal in such unsupervised learning problems may be to discover groups of similar examples within the data, where it is called clustering, or to determine how the data is distributed in the space, known as density estimation. In contrast with sequence mining, association rule learning typically does not consider the order of items either within a transaction or across transactions. Association rules mining is another key unsupervised data mining method, after clustering, that finds interesting associations (relationships, dependencies) in large sets of data items.
Conclusion – Collecting and labelling a large set of sample patterns can be very expensive. How this type of learning helps business to see some potentials which is usually hidden normally. The goal in such unsupervised learning problems may be to discover groups of similar examples within the data, where it is called clustering, or to determine how the data is distributed in the space, known as density estimation. In contrast with sequence mining, association rule learning typically does not consider the order of items either within a transaction or across transactions. Association rules mining is another key unsupervised data mining method, after clustering, that finds interesting associations (relationships, dependencies) in large sets of data items.
#MachineLearning #UnsupervisedMachineLearning
Books Referred
- Proceedings of the 2015 International Conference on Communications, Signal processing, and System.
- Artificial Intelligence: A Modern Approach
============================ About the Author =======================
Read about Author at : About Me
Thank you all, for spending your time reading this post. Please share your feedback / comments / critics / agreements or disagreement. Remark for more details about posts, subjects and relevance please read the disclaimer.
FacebookPage ContactMe Twitter ====================================================================

Nice complied work … pls add some real business use cases which your key or golden point and I read your posts for that you are now becoming my mentor
[…] to improve upon. On high level we got three main type of Machine Learning types i.e. Supervised, Unsupervised and Reinforcement learning. Since this post is limited to supervised learning and what it is doing […]
[…] For original post, click here […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs. […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs. […]
[…] This post talks about reinforcement machine learning only. Previous post on Supervised Learning and Unsupervised Learning are […]
[…] find previous posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] You can find our posts on Basic Machine Learning Understanding, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement Learning here. Also we now have post in details for “The new […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs. […]
[…] All credits if any remains on the original contributor only. We have covered supervised machine learning where we make predictions from labeled historical data. In the past post we have walked through unsupervised machine learning. […]
[…] find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] here is either very less or waiting for the data. Last posts on Supervised Machine Learning and Unsupervised Machine Learning got some decent feedbacks . Our next post will talk about Reinforcement Learning — Markov […]
[…] find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement […]
[…] All credits if any remains on the original contributor only. We have covered supervised machine learning where we make predictions from labeled historical data. In the past post we have walked through unsupervised machine learning. […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs. […]
[…] All credits if any remains on the original contributor only. We have covered supervised and unsupervised machine learning where we make predictions from labelled historical data and find patterns from unlabeled data. In the past post, we have walked through unsupervised machine learning. […]
[…] can find earlier posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs. […]
[…] All credits if any remains on the original contributor only. We have covered supervised and unsupervised machine learning where we make predictions from labelled historical data and find patterns from unlabeled data. In the past post, we have walked through unsupervised machine learning. […]
[…] posts on Machine Learning – The Helicopter view, Supervised Machine Learning, Unsupervised Machine Learning, and Reinforcement […]
[…] All credits if any remains on the original contributor only. We have covered supervised machine learning where we make predictions from labelled historical data. In the past post, we have walked through unsupervised machine learning. […]
Thanks for sharing. We read many of your blog posts, cool, your blog is very good.
[…] very less or waiting for the data. Last posts on Supervised Machine Learning and Unsupervised Machine Learning got some decent feedback. Our next post will talk about Reinforcement […]