Convolutional Neural Networks – CNNs Inspired by the architecture of the cerebral cortex, CNNs mimic how our brains process visual information. Now, before anyone gets too excited, let’s be real—CNNs are light-years away from the complexity of the human brain.

They’re like comparing a toddler’s doodle to a Picasso masterpiece—impressive, but not the same league. That said, I’m not diving into neuroscience here (trust me, that’s a rabbit hole I’m not academically equipped to navigate). Instead, let’s keep it practical and digestible. This post is all about synthetic intelligence—not in a dystopian, sci-fi way, but in plain English and at a high level so it actually makes sense.
Now, if you’re expecting mind-reading AI, hold that thought. CNNs are great, but they’re still pattern recognition workhorses—not digital Einsteins. They excel at identifying cats in photos, tumors in scans, and fraud in transactions, but they won’t debate philosophy with you (at least, not yet). So, as we unpack this AI magic, think of CNNs as the eyes of modern AI—sharp, specialized, and ever-learning, but still very much a tool, not a thinker.
- Deep Learning – Introduction to Recurrent Neural Networks
- Deep Learning – Deep Convolutional Generative Adversarial Networks Basics
- Deep Learning – Backpropagation Algorithm Basics
AILabPage defines Deep learning is “undoubtedly a mind-blowing synchronization technique applied on the basis of three foundation pillars: large data, computing power, skills (enriched algorithms), and experience, which practically has no limits.
What is Deep Learning?
Deep learning is a subfield of the machine learning domain. Deep learning is entirely concerned with algorithms inspired by the structure and function of artificial neural networks, which are inspired by the human brain (inspired only, please).

Deep learning is used with too much ease to predict the unpredictable. In our opinion, “we are all so busy creating artificial intelligence by using a combination of non-biological neural networks and natural intelligence rather than exploring what we have in hand. Deep learning is performed by a specialist with a complex skillset in order to achieve better results from the same data set than what could be achieved without it. It makes amazing attempts to mimic the natural intelligence (NI) mechanics of the biological neuron system.

“I think people need to understand that deep learning is making a lot of things, behind the scenes, much-better” – Sir Geoffrey Hinton
Deep learning prioritizes the acquisition of data representations as its foundational approach to learning. It has a complex skill set because of the methods it uses for training, i.e., learning in deep learning is based on “learning data representations” rather than “task-specific algorithms,” which is the case for other methods.
Human Brain: It is a special or critical point of discussion for everyone and a puzzling game of all times as well. How our brain is designed and how it functions we can’t cover in this post as I am nowhere close or even can dream to be close to a neuroscientist. Out of curiosity, I am tempted to compare artificial neural networks with the human brain (with the help of talk shows on such topics).

It’s fascinating to me to know how the human brain is able to decode technologies, numbers, puzzles, handle entertainment, understand science, set body modes into pleasure, aggression, art, etc. How does the brain train itself to name a certain object by just looking at 2-3 images when ANNs need millions of those?
Artificial Neural Networks
AILabPage defines artificial neural networks (ANNs) as “Biologically inspired computing code with a number of simple, highly interconnected processing elements for simulating (only an attempt) human brain working and processing information models.”

It’s way different than a computer program, though. There are several kinds of Neural Networks in deep learning. Neural networks consist of input and output layers and at least one hidden layer.
- Multi-Layer Perceptron
- Radial Basis Network
- Recurrent Neural Networks
- Generative Adversarial Networks
- Convolutional Neural Networks.
In this discussion, we delve into the realm of Convolutional Neural Networks (CNNs), exploring their nuances and applications. While our primary focus remains on CNNs, we also touch upon Region-based Convolutional Neural Networks (R-CNNs) for broader context.

This post and the mind map (above), provides an in-depth exploration of CNNs, elucidating their architectural intricacies, training methodologies, and pivotal components. Through this exploration, we aim to shed light on the practical implementations and real-life business use cases of CNN technology.

Neural Network Algorithms are like tech-savvy problem-solvers that use radial basis functions as their secret sauce. Think of them as super-smart tools that can be strategically applied to tackle different challenges.
Convolutional Neural Networks (CNN) – Outlook
Ok, now let’s start with our main topic, which is CNNs. CNNs rely on convolutional layers, which act like mini feature detectors. They start simple—detecting edges and textures—and then get more sophisticated, identifying shapes, objects, and even complex scenes. It’s like peeling an onion, layer by layer, but instead of making you cry, it makes AI smarter.

Now, CNNs—what are they exactly? A special breed of machine learning models designed to process structured, grid-based data.
- EcoSystem AI – The boss of its own environment, fully in control, self-sustaining, and running the show. Like a 007 Agent, who has full autonomy and decision-making power. I have heard of it and some scholarly papers.
- CNNs – Oh yes, my second favorite! The workhorse of modern AI, especially when it comes to understanding images and videos.
- The ultimate combo – The perfect blend of the first two. Think of it as AI with a supercharged visual cortex. It is my dream to have.’
My all-time topics of discussion are mentioned as above—and trust me CCNs, are in my top three right alongside Packages!
In simpler terms, means they excel at image and video analysis. They’re built to automatically learn patterns from visual data, much like how we instinctively recognize faces, objects, or even memes (yes, AI gets memes now—scary, right?).
CNNs: The Eyes of AI
CNNs are highly successful in tasks like image classification, object detection, and image generation. When a filter is applied to the input, it will cause the activation to happen. This is a simple and easy thing to do. A feature map is made by using a filter many times on an input. This shows where the features are and how strong they are in the input.

A common application of CNNs is in computerized vision tasks such as the classification of images, the detection of objects within them, and the segmentation of images.
- Deep Learning – Introduction to Recurrent Neural Networks
- Deep Learning – Deep Convolutional Generative Adversarial Networks Basics
- Deep Learning – Backpropagation Algorithm Basics
CNNs represent a powerful class of neural networks renowned for their prowess in tasks like image recognition, processing, and classification.

Firstly, let’s delve into convolution, a process where filters are applied to the input image using predefined parameters. This step, akin to applying a magnifying glass to certain parts of the image, helps identify important features. Strides dictate how these filters move across the image, while padding ensures consistency in processing. After convolution, activation functions like ReLU (Rectified Linear Unit) are applied, enhancing the network’s ability to capture nonlinear relationships within the data.
Convolutional Neural Networks are a special kind of multi-layer neural networks.
The process of convolution, pooling, and activation forms the backbone of CNNs, underpinning their remarkable success. It’s imperative to execute this process meticulously, as any misstep can compromise the network’s performance. By understanding these fundamental principles, we unlock the potential of CNNs to revolutionize image analysis and beyond
In short, CNNs are the eyes and pattern detectors of AI—breaking down images in ways we take for granted, but machines find remarkable. And yes, they still have a long way to go before they rival human perception, but hey, give them time.
CNNs: Science, Math, and Magic
Convolutional neural networks, usually appear like magic to many, but in reality, they are a simple combination of science and mathematics. These networks are a class of neural networks that have proven very effective in areas of image recognition, this in most cases, they are applied to image processing.

CNNs have had huge adoption and success within computer vision applications, but mainly with supervised learning as compared with unsupervised learning, which has gotten very little attention.
This network is a great example of variation in multilayer perceptrons for processing and classification. It’s a deep learning algorithm in which it takes input as an image, applies weights and biases effectively to its objects, and is finally able to differentiate images from each other.
As per Wiki: “In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks, most commonly applied to analyzing visual imagery.
They have existed for several decades but have been shown to be very powerful when large labelled datasets are used. This requires fast computers (e.g., GPUs)!
The artificial intelligence solutions behind CNN amazingly transform how businesses and developers create user experiences and solve real-world problems. CNN is also known as the application of neuroscience to machine learning. They employ mathematical operations known as “convolution,” which is a specialized kind of linear operation.

Convolutional neural network applications include high-calibre AI systems such as AI-based robots, virtual assistants, and self-driving cars. For image processing, the filters scan through the image to pass the feature map, which gets generated for each filter. Adding more and more filtering layers along with creating more feature maps generally allows abstracts for creating deeper CNN. Other common applications are used for
- Image Processing
- Recognition
- Classification
- Video labelling
- Text analysis,
- Speech Recognition
- Natural language processing
- Text classification processing
Convolutional Neural Network applications solve many unresolved problems that could have remained unsolved without CNN layers, including high-caliber AI systems such as AI-based robots, virtual assistants, and self-driving cars.
Other common applications where CNNs are used, as mentioned above, are emotion recognition, estimating age and gender, etc. The best-known models are convolutional neural networks and recurrent neural networks.
Some history around – Convolutional Neural Networks
Convolutional Neural Networks (CNNs) stand as a cornerstone in the field of computer vision, reshaping how machines perceive and interpret visual information. Developed by Yann LeCun in the late 1980s, CNNs experienced significant refinement, with LeNet5 emerging as a breakthrough architecture. Named after LeCun’s numerous iterations, LeNet5 showcased the potential of CNNs in deep learning.

The pivotal moment for CNNs came in 2012 when Alex Krizhevsky’s CNN model dominated the ImageNet competition, marking a turning point in computer vision research. This victory spurred widespread adoption and fueled a race among tech giants to leverage CNNs for various applications.
- Versatile AI Models: CNNs are essential in various fields, including facial recognition and object detection for autonomous vehicles.
- Hierarchical Feature Learning: They automatically extract and learn features from raw data, making them highly adaptable for numerous tasks.
In the 1990s, LeNet’s architecture primarily targeted character recognition tasks, such as reading zip codes and digits. However, the continuous evolution and refinement of CNNs have expanded their scope to encompass a wide range of visual recognition challenges, cementing their status as one of the most influential innovations in computer vision.
Training Convolutional Neural Networks
Training a CNN involves feeding batches of data through the model, computing loss, and updating weights using optimization techniques. The trained CNN can then be evaluated on validation or test sets and used for making predictions on new, unseen data. CNNs play a crucial role in advancing image recognition, object detection, and other visual understanding tasks, revolutionizing industries such as healthcare, autonomous driving, and security.

As depicted in above diagram the AILabPage_User trains the CNN model by providing data batches, which are received and processed by the model. During training, the CNN computes loss and updates weights using optimization techniques iteratively. Once trained, the CNN can be evaluated on validation or test sets to assess its performance, or used to make predictions on new data. Deep learning frameworks like TensorFlow facilitate the implementation of CNNs by providing essential tools and resources.
| # | Step | Description | Key Actions |
|---|---|---|---|
| 1 | Data Preparation | – Load the image of a deer in a green jungle (32×32 pixels, R, G, B channels). – Preprocess by resizing, normalizing, and applying data augmentation (e.g., rotation, flipping). | – Load & preprocess image – Normalize pixel values – Apply augmentation |
| 2 | Model Initialization | – Initialize a CNN model with convolutional layers, pooling layers, fully connected layers, and an output layer. – Randomly initialize weights and biases or use pre-trained weights. | – Define CNN architecture – Initialize parameters |
| 3 | Forward Propagation | – Pass the preprocessed deer image through the CNN model. – Perform convolutions + ReLU activation to extract features. – Apply pooling to downsample features and flatten the output for fully connected layers. | – Forward pass image – Feature extraction with ReLU – Downsample using pooling |
| 4 | Loss Computation | – Compute loss/error between predicted probabilities and the true label (“deer”) using categorical cross-entropy. – Quantify model performance by measuring discrepancy between predicted and actual labels. | – Compute loss function – Compare predictions with actual label |
| 5 | Backward Propagation | – Use backpropagation to compute gradients of the loss function w.r.t. model parameters. – Update weights and biases to minimize loss. | – Compute gradients – Adjust weights & biases |
| 6 | Parameter Update | – Optimize model using Stochastic Gradient Descent (SGD) or other optimizers. – Update parameters based on computed gradients and learning rate. | – Use optimization algorithm – Apply parameter updates |
| 7 | Iteration | – Repeat forward & backward propagation for multiple epochs using training batches. – Each iteration refines model parameters. | – Train model over multiple iterations – Process data in batches |
| 8 | Evaluation | – Monitor model performance using a validation dataset. – Compute metrics like accuracy & loss to detect overfitting. | – Evaluate on validation set – Monitor performance |
| 9 | Termination | – Stop training when performance plateaus or after reaching a max epoch limit. – Avoid overtraining. | – Apply stopping criteria – Prevent overfitting |
| 10 | Testing | – Evaluate the trained model on a test dataset (unseen deer images and other objects). – Assess generalization using accuracy & loss metrics. | – Test model on unseen data – Compute final performance metrics |
The combination of convolutional layers, pooling layers, and fully connected layers allows CNNs to capture intricate patterns and relationships in images, making them invaluable for various computer vision tasks. With the availability of deep learning frameworks like TensorFlow, implementing CNNs has become more accessible, enabling researchers and practitioners to leverage the power of CNNs in their applications. As technology continues to advance.
Data Processing – Convolutional Neural Network
CNN has a grid topology for processing data. Data points in this topology are called grid-like, as the processing of data happens in a spatial correlation between the neighbouring data points.

- 1D Grid – Time series data – Takes samples at regular time intervals
- 2D Grid – Image data – Grid of pixels
These neural networks use the convolution method as opposed to general matrix multiplication in at least one of the layers. Convolution leverages on
- Equivariant Representations – This simply means that if the input changes, the output changes in the same way
- Sparse Interactions – This allows the network to efficiently describe complicated interactions between many variables using simple building blocks.
- Parameter sharing – Using the same parameter for more than one function in a model
The above structure was created to improve a machine-learning system. CNN also allows for working with inputs of variable size and efficiently describing complicated interactions between many variables from simple building blocks.

There are significant limitations to these neural networks at the API level. Input, e.g., an image, and output, e.g., classes of probabilities, are both fixed-size vectors. Even the computation through its data models is performed by mapping using a fixed number of layers.
Image Processing – Human vs Computers
For humans, the recognition of objects is the first skill we learn right from birth. A newborn baby starts recognizing faces as Papa, Mumma, etc. By the time you turn into an adult, recognition becomes effortless and a kind of automated process.

Human behavior for processing images is very different from that of machines. Humans give a label to each image automatically by just looking around and immediately characterizing the scene and giving each object a label without even consciously noticing.
For computers, recognizing objects is slightly complex as they see everything as input and output, which come as a class or set of classes. This is known as image processing, which we will discuss in detail in the next section. In computers, CNNs do image recognition and image classification.

It is very useful in object detection, face recognition, and various text classification tasks with word embedding, etc. So in simple words, computer vision is the ability to automatically understand any image or video based on visual elements and patterns.
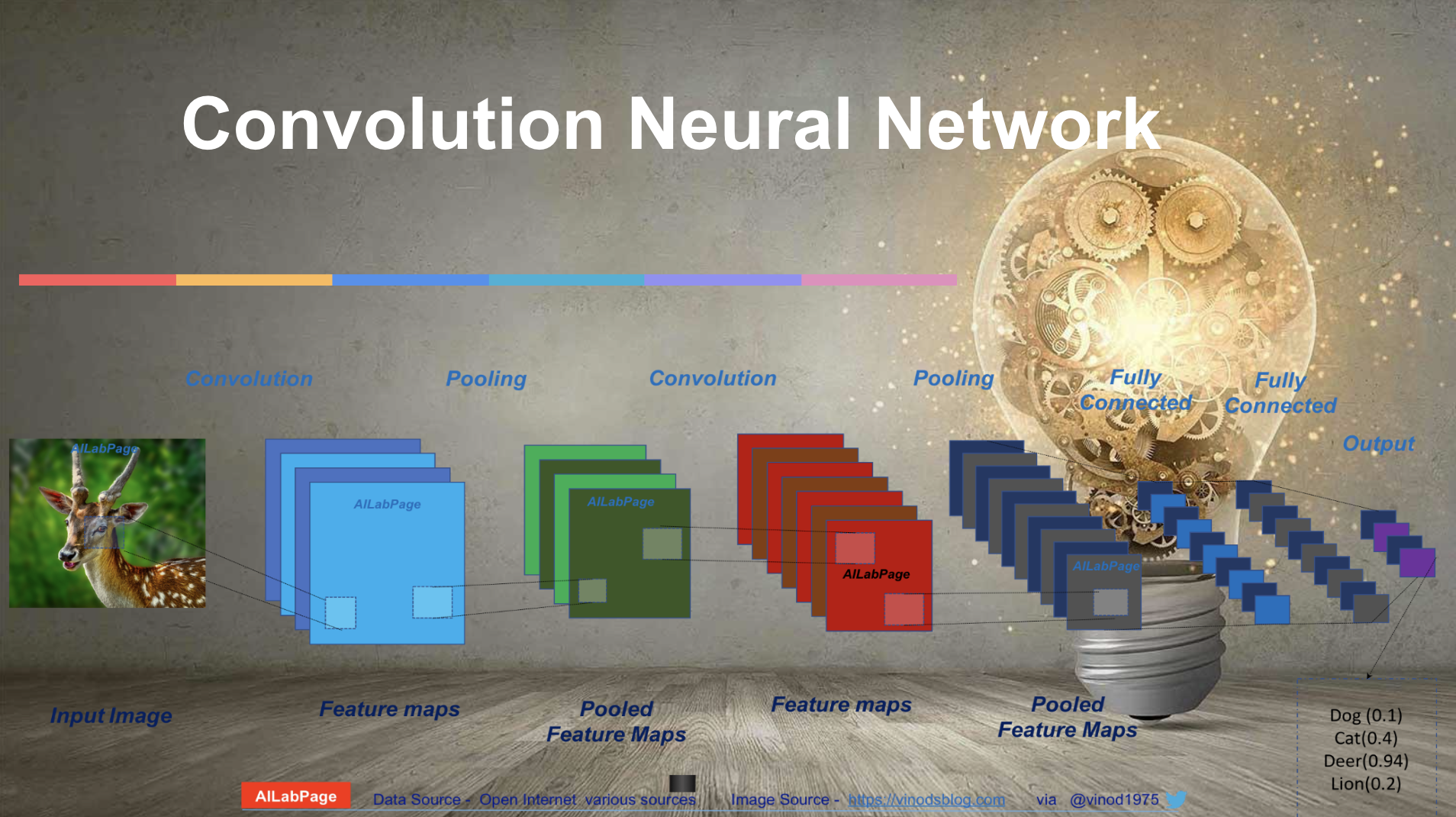
CNN Architecture – Deciphering Image Analysis
In this process, Our focus will be on image processing only, we’ll outline the step-by-step operation of a Convolutional Neural Network (CNN) architecture using an image of a deer in a jungle as input. Each stage, from initial feature extraction to final prediction generation, will be meticulously described, illuminating the intricate workings of CNNs in image analysis tasks.

CNN requires models to train and test. Each input image passes through a series of convolution layers with filters (Kernels), pooling, and fully connected layers (FC) and applies the softmax function (a generalization of the logistic function that “squashes” a K-dimensional vector of arbitrary real values into a real Kd vector) to classify an object with probabilistic values between 0 and 1. This is the reason every image in CNN gets represented as a matrix of pixel values.
Input Image
The raw input data is the image of a deer in a green jungle, with a width of 32 pixels, a height of 32 pixels, and three color channels (red, green, and blue). Each pixel’s intensity values range from 0 to 255.
import numpy as np
input_image = np.random.rand(32, 32, 3)
Convolutional Layer 1
The convolution and pooling layers act as feature extractors from the input image, while a fully connected layer acts as a classifier. In the above image figure, on receiving a dear image as input, the network correctly assigns the highest probability for it (0.94) among all four categories.

The sum of all probabilities in the output layer should be one, though. There are four main operations in the ConvNet shown in the image above:
- Convolution Operation: The input image is convolved with a set of learnable filters, also known as kernels or feature detectors. Each filter slides across the input image, computing dot products with local regions to extract various features.
- Feature Map Generation: The convolution operation produces multiple feature maps, each highlighting different patterns or features present in the input image.
- Apply the convolution operation to the input image using the defined layer.
- Add a bias term to the convolved output.
- Apply an activation function, such as ReLU, to introduce non-linearity.
- Lets assume the output probabilities for image above are [0.2, 0.1, 0.3, 0.4]
- The size of the feature map is controlled by three parameters.
- Depth – Number of filters used for the convolution operation.
- Stride – number of pixels by which filter matrix over the input matrix.
- padding – It’s good to input matrix with zeros around the border, matrix.
- Calculating total error at the output layer with summation over all 4 classes.
- Total Error = ∑ ½ (target probability – output probability) ²
- Computation of output of neurons that are connected to local regions in the input. This may result in volume such as [32x32x16] for 16 filters.
from tensorflow.keras.layers import Conv2D
conv_layer1 = Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’)(input_image)
Each filter scans across the image, computing dot products between its weights and local patches of the image. This process generates feature maps that capture different image features.
ReLU Activation
The Rectified Linear Unit (ReLU) Layer serves as a crucial element in Convolutional Neural Networks (CNNs), adding non-linearity to the network and enabling it to learn complex patterns from the input data.

- Non-linear Transformation: Similar to the first convolutional layer, ReLU activation is applied to introduce non-linearity and enhance the network’s representational capacity.
Activation Function: Apply a non-linear activation function, such as ReLU (Rectified Linear Unit), to introduce non-linearity into the model. ReLU sets negative values to zero and keeps positive values unchanged, helping the network learn more complex representations.
For instance, our input feature map size is [32x32x16], applying ReLU to it retains the same size of [32x32x16]. ReLU introduces non-linearity to the network, allowing it to model complex relationships and make nonlinear transformations of the input data. This non-linear behavior is essential for the network to learn and represent intricate patterns and features present in the input data, which may not be captured by linear operations alone.

We now apply an activation function again, such as ReLU or sigmoid, to the outputs of fully connected layers to introduce non-linearity and ensure the model can learn complex mappings.
Overall, the ReLU Layer plays a critical role in CNNs by enabling the network to learn sophisticated representations of the input data and thus improving its ability to perform tasks such as image classification, object detection, and segmentation.
Pooling Layer 1
- Max-Pooling Operation: The feature maps obtained from the convolutional layer are downsampled using a max-pooling operation. Max-pooling extracts the most prominent features by selecting the maximum value within each pooling region.
- Dimensionality Reduction: Max-pooling reduces the spatial dimensions of the feature maps, making subsequent computations more efficient while preserving essential features.
from tensorflow.keras.layers import MaxPooling2D
pool_layer1 = MaxPooling2D(pool_size=(2, 2))(conv_layer1)
Convolutional Layer 2
- Convolution Operation: The downsampled feature maps from the first pooling layer undergo another round of convolution with a new set of learnable filters.
- Feature Hierarchy Learning: The second convolutional layer learns higher-level features by combining lower-level features learned from the previous layer.
conv_layer2 = Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)(pool_layer1)
ReLU Activation
- Non-linear Transformation: Similar to the first convolutional layer, ReLU activation is applied to introduce non-linearity and enhance the network’s representational capacity.
Pooling Layer – 2
- Max Pooling operation on a Rectified Feature map.
So remember pooling layer does downsample the feature maps generated by convolutional layers.
- Define a pooling layer with specified parameters, such as pool size and stride.
- Apply the pooling operation to the output of the previous convolutional layer.

Also called subsampling or downsampling. The pooling layer does a downsampling operation along the spatial dimensions (width and height), resulting in a volume such as [16x16x16], i.e., it reduces the dimensionality of each feature map but retains the most important information.
- Max-Pooling Operation: The feature maps generated by the second convolutional layer are further downsampled using max-pooling to capture the most salient features.
- Spatial Information Reduction: Pooling reduces the spatial resolution of the feature maps while retaining essential information, aiding the network in focusing on the most discriminative features.
from tensorflow.keras.layers import MaxPooling2D
pool_layer1 = MaxPooling2D(pool_size=(2, 2))(conv_layer1)
Common pooling operations include max pooling, where the maximum value in each region is retained, or average pooling, where the average value is taken. Pooling reduces spatial dimensions while preserving important features.
Flattening
- Data Restructuring: The pooled feature maps are flattened into a one-dimensional vector, preserving the spatial hierarchy of features while converting them into a format suitable for processing by fully connected layers.
- Vector Representation: Flattening transforms the multi-dimensional feature maps into a linear array, preparing the data for input to the fully connected layers.
from tensorflow.keras.layers import Flatten
flattened_output = Flatten()(pool_layer2)
Fully Connected Layer – 1
In the fully connected layer, also known as the dense layer, each neuron is connected to every neuron in the adjacent layer. This connectivity allows for complex interactions and feature combinations to be learned. In the context of classification tasks, the fully connected layer computes class scores using a traditional multilayer perceptron architecture. This involves applying a softmax activation function to the output layer, resulting in a probability distribution over the different classes.
- Neuron Interconnection: The flattened feature vector is fed into a densely connected layer, where each neuron is connected to every neuron in the next layer.
- Feature Abstraction: Fully connected layers learn abstract representations of the input data, capturing complex relationships between features extracted from the convolutional layers.

For example, in the CIFAR-10 dataset, which consists of 10 classes, the output layer produces a volume of size [1x1x10]. Each of the 10 numbers in this volume represents the score or probability assigned to a specific class.
(The image left I decided to replace my deer’s picture with my dear son)
Before reaching the fully connected layers, the input data undergoes several convolutional and pooling layers. These layers serve to extract and abstract features from the input images. Once the feature maps are generated, they are flattened into a one-dimensional vector and passed to the fully connected layers.
These layers play a crucial role in learning high-level representations of the input data by connecting every neuron from the flattened feature maps to neurons in the fully connected layer. This dense connectivity enables the network to learn complex patterns and relationships present in the data, ultimately facilitating accurate classification or prediction tasks
- Flatten the output from the last pooling layer to a 1D vector.
- Define fully connected layers with specified number of neurons and activation functions.
- Connect the flattened output to the fully connected layers.
from tensorflow.keras.layers import Dense
fully_connected1 = Dense(units=128, activation=’relu’)(flattened_output)
fully_connected2 = Dense(units=64, activation=’relu’)(fully_connected1)
The main job of this layer is to basically take an input volume as it comes as output from Conv, ReLU, or pool layer proceedings. Arrange the output in an N-dimensional vector, where N is the number of classes that the program has to choose from.
Fully Connected Layer – 2
- Further Abstraction: An additional fully connected layer may be added to the network to extract higher-level features and relationships from the data.
- Representation Refinement: The second fully connected layer refines the learned representations, enabling the network to make more accurate predictions.
Output Layer
The final layer of the CNN is the output layer, which produces the network’s predictions. The number of neurons in this layer depends on the specific task, such as binary classification, multi-class classification, or regression. The activation function used in the output layer depends on the task as well.
- Prediction Generation: The final fully connected layer produces the network’s predictions by mapping the learned features to output classes or values.
- Activation Function: Depending on the task, an appropriate activation function (e.g., softmax for classification or linear for regression) is applied to the output layer to generate probability distributions or continuous predictions.
output_layer = Dense(units=num_classes, activation=’softmax’)(fully_connected2)
Through this detailed examination, we’ve unraveled the complex processing involved in a CNN architecture. From the extraction of low-level features to the generation of high-level abstractions, each step contributes to the network’s ability to understand and interpret visual data, ultimately enabling accurate predictions and insights.
CNN – Challenges
CNNs revolutionized image classification and analysis, but they face hurdles like vanishing/exploding gradients, overfitting, and data quality issues. Understanding and mitigating these challenges are crucial for enhancing CNN performance and advancing computer vision applications.

- Vanishing/Exploding Gradients: CNNs may suffer from gradients becoming extremely small or large during training, hindering effective weight updates and model convergence.
- Data Quality Issues: Poor quality or insufficient training data can lead to biased models, limiting their ability to generalize to new, unseen data.
- Overfitting: CNNs may memorize training data instead of learning underlying patterns, resulting in poor performance on unseen data and reduced model generalization.
It encounter obstacles such as vanishing/exploding gradients, overfitting, and data quality concerns. Addressing these challenges is essential for improving CNN performance and ensuring accurate image analysis in various fields like healthcare, autonomous vehicles, and security systems.
Convolutional Neural Networks – Real-life Business Use Cases
Many modern companies use CNNs as their business’s backbone; for example, Pinterest uses it for home feed personalization, and Instagram uses it for search infrastructure. Three of the biggest users are listed below.

- Automatic Tagging Algorithms: Tagging, or social bookmarking, refers to the action of associating a relevant keyword or phrase with an entity (e.g., a document, image, or video). Our experiment (above) showed us that effective time-frequency representation for automatic tagging and more complex models benefit from more training data.
- Photo Search: To find images that are similar to the user’s input or text input, use the Google search results. It works well on the Chrome app. Google’s algorithms rely on more than 200 unique signals, or “clues,” that make it possible to guess a search. Attributes here are websites, the age of content, IP address-based regions, and PageRanks. Sadly, this is highly biased based on your color of skin. You can give it a try, though.
- Product Recommendations: Large-scale recommender systems are in use in almost every e-commerce, retail, video-on-demand, or music-streaming business. Algorithms in recommender systems are typically classified into two categories: content-based and collaborative filtering methods, although modern recommenders combine both approaches.
These companies leverage CNNs to personalize content and improve search accuracy, demonstrating the widespread adoption and impact of convolutional neural networks in modern technology-driven businesses.

The process of a CNN entails four crucial stages: convolution, pooling, flattening, and full connection. These steps were comprehensively explored. Decide on the parameters, apply filters using strides, and include padding if necessary. Apply convolution to the image, followed by matrix activation using ReLU. The fundamental process at CNN, which is crucial to its success, is immensely important. If it is not correctly executed, the entire process is doomed to fail.

Conclusion- An endeavor was made in this article to elucidate the fundamental ideas behind convolutional neural networks in plain language. Convolutional Neural Networks (CNNs) are powerful deep learning models specifically designed for image recognition and processing tasks. By leveraging the hierarchical structure of convolutional layers, pooling layers, and fully connected layers, CNNs excel at extracting meaningful features from images and making accurate predictions. The step-by-step process outlined above demonstrates the key components and operations involved in building a CNN, from data preparation and convolutional layers to pooling, fully connected layers, and optimization.
—
Books Referred & Other material referred
Points to Note:
All credits, if any, remain with the original contributor only. We have covered the convolutional neural network, a kind of machine learning, in this post, where we find hidden gems from unlabeled historical data. The last post was on supervised machine learning. In the next post, I will talk about reinforcement machine learning.
Feedback & Further Question
Do you have any questions about deep learning or machine learning? Leave a comment or ask your question via email. I will try my best to answer it.
============================ About the Author =======================
Read about Author at : About Me
Thank you all, for spending your time reading this post. Please share your opinion / comments / critics / agreements or disagreement. Remark for more details about posts, subjects and relevance please read the disclaimer.
FacebookPage ContactMe Twitter ====================================================================

Excellent post you made such complex subject easy to understand. In the last few years, the deep learning (DL) computing paradigm has been deemed the Gold Standard in the machine learning (ML) community. Moreover, it has gradually become the most widely used computational approach in the field of ML, thus achieving outstanding results on several complex cognitive tasks, matching or even beating those provided by human performance.
Thank you
Hi,
This is the latest booming technology to learn more about it your post help me.
Wonderful illustrated information. I thank you for that. No doubt it will be very useful for my future projects. Would like to see some other posts on the same subject!
Thank you for sharing…
Simple and easy to understand …
Several published DL review papers have been presented in the last few years. However, all of them have only been addressed one side focusing on one application or topic such as the review of CNN architectures, DL for classification of plant diseases, DL for object detection, DL applications in medical image analysis, and etc.
You blog in first place present the required to understand DL aspects including concepts, challenges, and applications then going deep in the applications. To achieve that, it requires extensive time and a large number of research papers to learn about DL including research gaps and applications. Therefore, we propose a deep review of DL to provide a more suitable starting point from which to develop a full understanding of DL from one review paper.
This is very high level info not much of details to learn.
Do we loose any information when using a feature detector at Convolution + Pooling layers which act as feature extractors?
I am student and worker at same time and I loved your narrative Convolutional Neural Networks are very similar to ordinary Neural Networks from the previous. Please help to answer in details how the flow to FCL happens, pls let me know bit by bit
Great post! Thanks. so much for the work for people like me really appreciate. I have few questions though if you can answer please
1 – What makes convolutional filters in the first convolutional layer “unique”?
2 – Are all 5×5 filters have same behaviour.
3 – Are they just being passed through different non-linear functions or something?
4 – Why don’t they produce the same representations?
5 – What informs such decisions? makes
[…] credits if any remains on the original contributor only. Last post was on Convolutional Neural Networks. In the next upcoming post will talk about Reinforcement machine […]
[…] Convolutional Neural Networks […]
[…] classifier to determine input. Whether given input looks like real or fake. Discriminator works as convolutional neural network architecture call […]
[…] Convolutional Neural Networks. […]
Love it, The data is fed into the model and output from each layer is obtained from the above step is called feedforward, we then calculate the error using an error function, some common error functions are cross-entropy, square loss error, etc. The error function measures how well the network is performing. After that, we backpropagate into the model by calculating the derivatives.
Greate post, I think you are mising on showing or hiding the down side which are as below, you may add it tou your post if you want. CNNs have many drawback than a weakness.
Convolutional neural networks like any neural network model are computationally expensive. This can be overcome with better computing hardware such as GPUs and Neuromorphic chips.
IN CNNs has issues in class imbalance and overfitting when there many classes (+/- 50 classes).
Something that a lot of people are concerned about is that no theory gives bounds on the amounts of layers to be used, therefore, it is usually a trial and error thing.
[…] or neural networks or neural nets. There are some specialized versions also available. Such as convolution neural networks and recurrent neural networks. These addresses special problem domains. Two of the best use […]
This is super basic but very very informative and useful info for people to start with. I would love to see part-2 and subsequent parts to check for details. Seriously you are helping students and professional a lot, keep writing and keep learning. Many Many Thanks for London School
[…] Convolutional neural network – CNN’s are inspired by the structure of the brain but our focus will not be on neural science here as we do not have any expertise or academic knowledge in any of the biological aspects. We are going artificial in this post. CNN’s are a class of Neural Networks that have proven very effective in areas of image recognition, processing, and classification. In this article, we will explore and discuss our intuitive explanation of convolutional neural networks (CNN’s) on a high level and in simple language. […]
Your amazing insightful information entails much to me and especially to my peers. Thanks a ton; from all of us. ExcelR Machine Learning Course Pune
[…] Link : https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
[…] Convolutional Neural Networks – CNN a neural network with some convolutional and other layers. The convolutional layer has a number of filters that do a convolutional operation. In other words, CNN’s are a class of Neural Networks that have proven very effective in areas of image recognition processing, and classification. […]
Your amazing insightful information entails much to me and especially to my peers. Thanks a ton; from all of us. ExcelR Machine Learning Course
[…] can be used to overcome the shortcoming of CNN’s? etc. I guess if you read this post on “Convolutional Neural Networks“; you will find out the […]
[…] https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
[…] https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
[…] https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
[…] Convolutional Neural Network Architecture. Source […]
[…] Read the complete article at: vinodsblog.com […]
[…] Sharma, V. (2018). https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
[…] Sharma, V. (2018). https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/ […]
The project was done in the Spring 2021 semester for the Advanced Artificial Intelligence (CS 591) Class. The project topic was “Sound Classification using Deep Learning”. I choose this project because Sound Classification is one of the most generally used applications in Audio Deep Learning.
Deep learning is a subset of machine learning in which multi-layered neural networks are modeled to work like the human brain – ‘learn’ from a large amount of data. The use of deep learning in an automation environment is growing. Such as personal security to critical surveillance, classifying music clips to identify the genre of the music, or classifying short utterances by a set of speakers to identify the speaker based on the voice. The learning capabilities of the deep learning architectures can be used to develop sound classification systems to overcome the efficiency issues of the traditional systems.
The project demonstrates the use of a deep learning algorithm, and CNN (Conventional neural network) to find the accuracy of the sound. Furthermore, python programming and its libraries, google collab was used to implement sound classification.6. INTRODUCTIONThe project goal is to differentiate the various type of sound (Urban Sound 8K dataset) using a Deep learning algorithm and visualizing them in the electromagnetic spectrum. Audio/Sound signals are all around us. Humans can differentiate, recognize sound through their and hearing senses, imagine how it will feel when a computer differentiates the sound using machine learning algorithms.
There is a growing interest in sound classification for different scenarios. For example, fire alarm detection for hearing impaired people, engine sound analysis for maintenance and patient monitoring in hospitals, etc. The project shows the use of Deep Learning techniques for the classification of different environmental sounds, specifically focusing on the identification of Urban Sounds. The result shows the accuracy of the sound, higher accuracy better prediction.6.1 Keywords1. Deep Learning algorithm to find the accuracy (Sound Classification).2. Google Colab, Python programing, packages, and its libraries.3.
Dataset, Urban Sound 8K, CSV that contains sound files.4. Dataset contains 8732 sound excerpts (< = 4s) of urban sounds from 10 classes.5. Visualization of sound prediction, accuracy in spectrogram using matplotlib.7. COLLECTIONS OF DATA FROM THE DATASET7.1 DatasetProject starts with the collection of the dataset downloaded from the given source UrbanSounds website.Fig 5:7.2 Segregation of Data into Various FoldersSegregate data into various folders, and then metadata is prepared (CSV file).Fig 6:8. WRITING CODE AND DATA MODELING/TRAININGThe python programming and jyputer notebook with the package Librosa, Keras, pandas, and matplotlib for visualization. The data sets are used to build and train a deep neural network for prediction.
Fruits, Vegetables and Deep Learning – Level Up Coding. Medium. https://levelup.gitconnected.com/fruits-vegetables-and-deep-learningc5814c59fcc9.%5B2%5D https://medium.com/swlh/building-a-deep-learning-model-with-pytorch-to-classify-fruits-and-vegetables-30e1a8ffbe8c%5B3%5D https://towardsdatascience.com/classification-of-fruit-images-using-neural-networks-pytorch-1d34d49342c7%5B4%5D https://blog.jovian.ai/fruits-classification-using-cnn-and-pytorch-bc583e6052d3%5B5%5D Sharma, V. “Deep Learning — Introduction to Convolutional Neural Networks”, 2018. https://vinodsblog.com/2018/10/15/everything-you-need-to-know-about-convolutional-neural-networks/. […]
[…] Convolutional Neural Networks. […]
[…] Convolutional Neural Networks. […]
[…] Convolutional Neural Networks. […]
[…] – While BMs were useful in the past, certain deep learning architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), have taken precedence over others because of their […]
Thank you for sharing this helpful information. You may find more information on this topic here Machine Learning Course in Pune
Thank you for sharing this helpful information. You may find more information on this topic here, Sevenmentor is a prestigious education training institute in Pune that offers a high-quality Machine Learning course. This course will teach you the fundamentals of Machine Learning.
[…] programs help to analyze images, sequence data and generate new content. These programs are called Convolutional neural networks (CNNs), Recurrent neural networks (RNNs), and Generative adversarial networks (GANs). These networks are […]
Well said “CNNs have revolutionized the field of computer vision and are essential in applications ranging from image classification and object detection to facial recognition and medical image analysis.”
[…] Convolutional Neural Networks […]
[…] Convolutional Neural Networks (CNNs) excelling in image processing to the bio-inspired dynamics of Spiking Neural Networks (SNNs), and […]
[…] Convolutional Neural Networks […]
[…] Convolutional Neural Network (CNN) – A neural networks, to do images recognition, processing and classifications. Objects detection, face recognition etc. are some CNN’s ability where it is widely used. […]
[…] Convolutional Neural Networks. […]
[…] Convolutional Neural Networks (CNNs) […]