Neural Networks Algorithms: Artificial Neural Networks arguably work close enough to the human brain. Conceptually, artificial neural networks are inspired by neural networks in the brain, but their actual implementation in machine learning is far from reality.

Artificial Neural Networks (ANNs) serve as a fundamental building block in the realm of artificial intelligence, mimicking the structure and functionality of the human brain’s neural networks. However, it’s crucial to recognize that while ANNs draw inspiration from biological neural networks, they are distinct entities with their own unique characteristics and mechanisms.
In this blog post, you and I will delve into the foundational concepts of artificial neural networks, shedding light on their underlying principles and operational intricacies. We’ll explore how ANNs process information, learn from data, and make predictions, providing you with a comprehensive understanding of their inner workings.
Additionally, we’ll take a closer look at various neural network algorithms, examining their roles in training neural networks, optimizing performance, and solving complex problems across diverse domains. Through this exploration, you’ll gain valuable insights into the practical applications and potential capabilities of artificial neural networks in real-world scenarios.
This is part 2 of the previous post, – Deep Learning: An Introduction to Artificial Neural Networks.
Artificial Neural Networks
AILabPage defines artificial neural networks (ANNs) as “Biologically inspired computing code with a number of simple, highly interconnected processing elements for simulating (only an attempt) human brain working and processing information models.”

It’s way different than a computer program, though. There are several kinds of Neural Networks in deep learning. Neural networks consist of input and output layers and at least one hidden layer.
- Multi-Layer Perceptron
- Radial Basis Network
- Recurrent Neural Networks
- Generative Adversarial Networks
- Convolutional Neural Networks.
Neural Network Algorithms are like tech-savvy problem-solvers that use radial basis functions as their secret sauce. Think of them as super-smart tools that can be strategically applied to tackle different challenges.

There are other models of neural networks out there, each with its own bag of tricks. If you’re curious about how these brainy algorithms operate and solve real mathematical problems, keep reading this post. It’s like peeking behind the curtain to understand their inner workings and see how they come to the rescue in the tech world.
ANNs learn, get trained, and adjust automatically, just as we humans do. Though ANNs are inspired by the human brain, they run on a far simpler plane. The structure of neurons is now used for machine learning, also called artificial learning. This development has helped various problems come to an end, especially where layering is needed for refinement and granular details are needed.
Exploring Neural Networks and Its EcoSystem
Neural network algorithms are important parts of modern machine learning. They imitate human brain activity to solve difficult problems. Neural networks are made of connected artificial neurons arranged in layers. They take input data and use weighted connections to process it, gradually transforming and improving the information.


Imagine you have a big box of different shapes and colors of toys, and you want to teach a robot to sort them. A neural network is like a smart robot brain that learns from examples.First, you show the robot some toys and tell it which ones are red and which ones are blue. The robot looks at the toys and tries to find patterns, like the red ones might be bigger or have more corners. It adjusts its brain connections to remember these patterns.
Then, you give the robot new toys it hasn’t seen before. It uses its brain to guess if they are red or blue based on the patterns it learned. Sometimes it might make a mistake, but it keeps learning and getting better.So, a neural network is like a helpful robot brain that learns from examples to figure out things, just like you learn from seeing and doing things many times.
During training, the weights change gradually using backpropagation to make the model’s predictions match the desired results. This helps neural networks to identify patterns, group data, and make predictions very accurately in different areas, like recognizing images and speech or diagnosing medical conditions.
Neural networks are becoming increasingly important in artificial intelligence and data analysis because they can easily adapt and process multiple things at the same time.
Neural Network Architecture
Neural networks consist of input, output, and hidden layers. The transformation of input into a valuable output unit is the main job. They are excellent examples of mathematical constructs. Information flow in a neural network happens in two ways.
Feedforward Networks
In these networks, signals only travel in one direction without any loop, i.e., towards the output layer. Extensively used in pattern recognition.
- At the time of it’s learning or “being trained”
- At the time of operating normally or “after being trained”

This network with a single input layer and a single output layer can have zero or multiple hidden layers. This method has two common designs, as above.
Feedback Networks
In this recurrent or interactive networks can use their internal state (memory) to process sequences of inputs. Signals can travel in both directions with loops in the network. As of now limited to time-series/sequential tasks. Typical human brain model.

Feedback Networks depict neural network architectures where feedback loops enable information to flow backward through the network, facilitating tasks like sequence modeling and memory retention. These networks often incorporate mechanisms such as recurrence, residual connections, and specialized memory units like Long-Short Term Memory (LSTM) cells.
Neural Network Algorithms works on three main layers of its architecture i.e input layer, hidden layer (though there can be many hidden layers) and output layer.
Neural Network Architectural Components
Neural network architectural components consist of Input Layers, where data is received; Neurons, the basic processing units; Weights, representing the strength of connections between neurons; Hidden Layers, performing intermediate computations; and Output Layers, producing final results. Activation Functions transform inputs into outputs.

Together, these components form the backbone of neural networks, enabling complex computations and pattern recognition. Each component plays a crucial role in processing information, making neural networks powerful tools for tasks such as image recognition, natural language processing, and predictive analytics.
- Input Layers, Neurons, and Weights: The basic unit in a neural network is called the neuron or node. These units receive input from an external source or some other nodes. The idea here is to compute an output-based weight associated with it. Weights are assigned to the neuron based on its relative importance compared with other inputs. Now finally, functions are applied to this for computations.
- Let’s assume our task is to make tea, so our ingredients will represent the neurons,” or input neurons, as these are building blocks or starting points. The amount of each ingredient is called a “weight.” After dumping tea, sugar, species, milk, and water in a pan, mixing will transform them into another state and color. This process of transformation can be called an “activation function”.
- Hidden Layers and Output Layers: The hidden layer is always isolated from the external world, hence its name. The main job of the hidden layer is to take inputs from the input layer and perform its job, i.e., calculate and transform the result into output nodes. A bunch of hidden nodes can be called a hidden layer.
- Continuing the same example above, in our tea-making task, now using the mixture of our ingredients coming out of the input layer, the solution, upon heating (the computation process), starts changing color. The layers made up of the intermediate products are called “hidden layers”. Heating can be compared with the activation process; in the end, we get our final tea as an output.
The network described here is much simpler for ease of understanding compared to the one you will find in real life. All computations in the forward propagation step and back-propagation step are done in the same way (at each node) as discussed before. Neural Network Algorithms
Neural Network Work Flow – Layers of Learning
The neural networks learning process is not very different from humans, humans learn from experiences in lives while neural networks require data to gain experience and learn. Accuracy increases with the amount of data over time. Similarly, humans also perform the same task better and better by doing any task they do over and over.

Neural Network Algorithms’ underlying foundation of neural networks is a layer and layers of connections. The entire neural network model is based on a layered architecture. Each layer has its own responsibility. These networks are designed to make use of layers of “neurons” to process raw data and find patterns in it and objects which are usually hidden by naked eyes. To train a neural network, data scientist put their data in three different baskets.
- Training data set – This helps networks to understand and know the various weights between nodes.
- Validation data set – To fine-tune the data sets.
- Test data set – To evaluate the accuracy and records margin of error.
Layer takes input, extract feature and feeds into the next layer i.e. each layer works as an input layer to another layer. This is to receive information and the last layer job is to throw the output of the required information. Hidden layers or core layers process all the information in between.
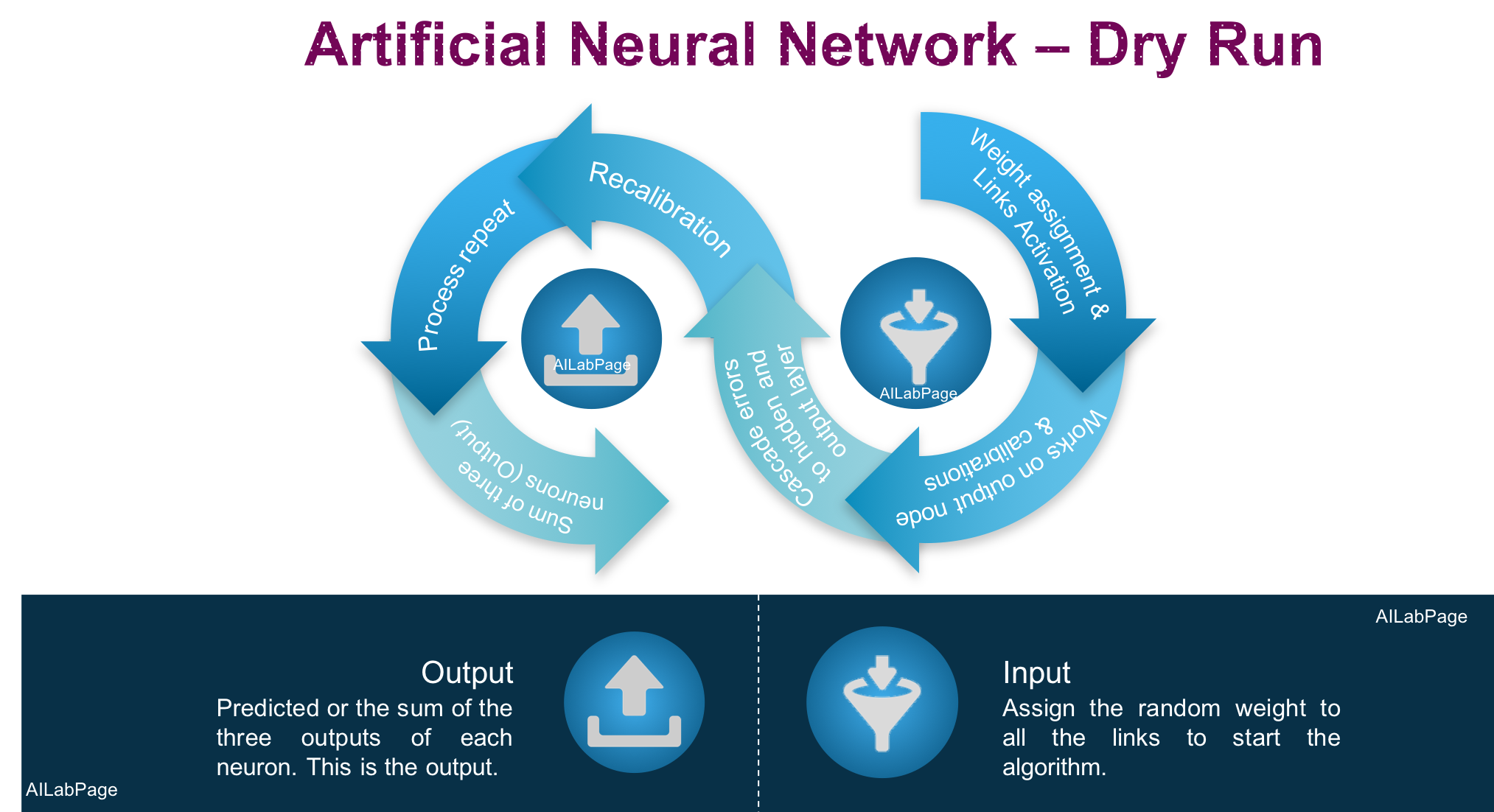
- Assign a random weight to all the links to start the algorithm.
- Find links to the activation rate of all hidden nodes by using the input and links.
- Find the activation rate of output nodes with the activation rate of hidden nodes and output link.
- Errors are discovered at the output node and to recalibrate all the links between hidden & output nodes are.
- Using the weights and error at the output; cascade down errors to hidden & output nodes. Weights get applied to connections as the best friend for neural networks.
- Recalibrate & repeat the process of weights between hidden and input nodes until the convergence criteria are met.
- Finally the output value of the predicted value or the sum of the three output values of each neuron. This is the output.
- Patterns of information are fed into the network via the input units, which trigger the layers of hidden units, and these, in turn, arrive at the output units.
Deep Learning’s most common model is “The 3-layer fully connected neural network”. This has become the foundation for most of the others. The backpropagation algorithm is commonly used for improving the performance of neural network prediction accuracy. It’s done by adjusting higher-weight connections in an attempt to lower the cost function.
Behind The Scenes – Neural Networks Algorithms
There are many different algorithms used to train neural networks with too many variants. Let’s visualise an artificial neural network (ANN) to get a fair idea of how neural networks operate.

By now we all know that there are three layers in the neural network.
- The input layer
- Hidden Layer
- The output layer
We outline a few main algorithms with an overview to create our basic understanding and the big picture behind the scene of these excellent networks.
- Feedforward algorithm
- Sigmoid – A common activation algorithm
- Cost function
- Backpropagation
- Gradient descent – Applying the learning rate
In neural networks, almost every neuron influences and is connected to each other as seen in the above picture. The above 5 methods are commonly used in neural networks.
The above diagram illustrates the intricate connections between neurons within a neural network, highlighting the extensive interdependence among them. This interconnectedness enables the network to perform complex computations and learn from data.
Additionally, the neural network employs various algorithms and techniques to train and optimize its performance. The five methods mentioned—feedforward algorithm, sigmoid activation, cost function, backpropagation, and gradient descent—are fundamental to the training and operation of neural networks. They play key roles in processing input data, adjusting network parameters, and improving the network’s predictive accuracy.
Recursive Neural Networks
Recursive Neural Networks, often likened to deep tree-like structures, are specifically designed for tasks involving the parsing of entire sentences. Unlike traditional feedforward or recurrent neural networks, which operate on linear sequences of data, recursive neural networks are adept at handling hierarchical structures inherent in natural language processing tasks.

The tree-like topology of recursive neural networks enables branching connections, allowing them to capture complex relationships between words and phrases within a sentence. By recursively applying neural operations at different levels of the tree structure, these networks can effectively process and analyze the compositional nature of language.
One of the key distinctions between recursive neural networks and recurrent neural networks lies in their approach to handling sequential data. While recurrent neural networks excel at modeling sequential dependencies over time, recursive neural networks focus on capturing hierarchical relationships within structured data, such as syntactic or semantic tree representations of language.
In essence, recursive neural networks offer a powerful framework for understanding and processing hierarchical structures in data, making them particularly well-suited for tasks such as natural language parsing and sentiment analysis.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) can be likened to deep tree-like structures, but their primary function extends beyond parsing sentences to understanding the contextual relationships within sequential data, such as speech, text, or music. Unlike feedforward neural networks, which process data in a strictly forward direction, RNNs are designed to allow information to loop through the network, enabling them to capture temporal dependencies and contextual nuances.

Similar to recursive neural networks, the tree-like topology of RNNs facilitates branching connections and hierarchical structures, albeit in the context of sequential data. These networks excel at modeling sequences by maintaining an internal state that evolves over time, allowing them to capture dependencies between elements of the sequence.
One notable feature of RNNs is their ability to process data in multiple directions, making them suitable for tasks requiring bidirectional analysis or prediction. This bidirectional data flow enables RNNs to analyze both past and future context when making predictions or generating output.
RNNs find applications in a wide range of complex tasks, including voice recognition, handwriting recognition, language modeling, and machine translation. By leveraging their ability to capture temporal dependencies and contextual information, RNNs contribute to advancements in various fields, from natural language processing to speech synthesis and beyond.
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) represent a significant milestone in the realm of deep learning, capturing the attention and resources of major corporations amidst the pervasive excitement surrounding artificial intelligence (AI). At their core, CNNs rely on two fundamental operations: convolution and pooling. These operations play a crucial role in extracting and simplifying essential features from complex datasets, facilitating the network’s ability to understand and interpret intricate information.

Operating through a hierarchical architecture consisting of interconnected layers, CNNs systematically process and refine data, enabling them to perform sophisticated tasks such as pattern recognition and analysis. This layered approach allows CNNs to progressively abstract and transform input data, ultimately leading to more accurate and nuanced outcomes.
In short, Convolutional Neural Networks (CNNs) stand as a testament to the power of deep learning, offering unparalleled capabilities in analyzing and interpreting complex data across diverse domains. As researchers and practitioners continue to explore and refine CNNs, their impact on technology and society is poised to grow exponentially in the years to come.
Generative Adversarial Networks
Generative Adversarial Networks (GANs) emerged as a breakthrough innovation, revolutionizing the landscape of machine learning and artificial intelligence.

Their inception in 2014 marked a pivotal moment in the quest for more powerful and versatile learning algorithms. GANs operate on a simple yet ingenious principle: two neural networks, the generator and the discriminator, engage in a perpetual game of cat and mouse, continually striving to outsmart one another.
This adversarial dynamic fuels the network’s ability to generate remarkably realistic data samples, mimicking the distribution of the training data with astonishing fidelity. Despite their relative youth, GANs have already found widespread application across diverse domains, from image and video synthesis to natural language processing and beyond.
Their capacity to unleash creativity and innovation continues to captivate researchers and practitioners alike, promising a future brimming with boundless possibilities. So as the name suggests it is called an Adversarial Network because this is made up of two neural networks. Both neural networks are assigned different job roles i.e. contesting with each other.
Example (Chess Game Between Me & My Son)
Lets assume two neural networks“, that compete as opponents of each other, for example, me(Vinod) and my son(Krishna). If I play chess continuously with my son, my game would surely improve because he is the best. On the back end of this scenario, I would analyze what I did wrong and what he did right. and learn from each mistake. Further, I need to think of a strategy that will help me beat my son in the next game and repeat until I win.
The setup involves a “Neural Network Duel”: two competing neural networks that simulate me and my son playing chess. As I play against my virtual opponent (simulating my son), the neural network observes and learns from my gameplay. After each match, the network analyzes my moves and compares them to the simulated “best” moves made by my son’s network. By identifying mistakes and strategic improvements, I iteratively refine my approach.
This process helps me strategize and adapt to my son’s virtual gameplay, aiming to formulate a winning strategy. Through continuous refinement, I will evolve my play style, ultimately seeking to triumph in the chess duel against my neural network opponent.
Working Of Example
To create a scenario as in the above example where two neural networks learn and adjust their strategies to play chess against each other, we can use a technique called “Reinforcement Learning” with a combination of neural network architectures such as Deep Q-Networks (DQN) or Policy Gradient methods. Here’s how it could work

- Algorithm Choice: Using a combination of Q-learning and neural networks.
- Q-learning is a type of reinforcement learning where an agent (the neural network) will learn to take actions in an environment (the chess game) to maximize a reward signal (winning the game).
- Network Architecture:
- Two Dueling Networks: Creating two separate neural networks, each representing a player (me and my son). These networks will estimate the “quality” of actions (moves) based on the current board state.
- Deep Q-Networks (DQNs): Each player’s neural network can be based on a DQN architecture, where the input is the encoded state of the chessboard, and the output is a Q-value for each possible move. These Q-values represent the expected future rewards if a particular move is chosen.
- Experience Replay:
- As I play against my virtual opponent (son’s neural network), record the sequence of states, actions, rewards, and next states. Store these experiences in a replay buffer.
- Learning Process:
- Q-Value Update: Periodically sample a batch of experiences from the replay buffer. For each experience, calculate the temporal difference error using the Bellman equation to update the Q-values of the neural network for the player who made the move.
- Policy Improvement: Using an exploration strategy (e.g., epsilon-greedy) to select moves during gameplay. Over time, balance exploration and exploitation to ensure that the networks continue to learn and improve their strategies.
- Adaptive Learning:
- As I analyze my gameplay and identify mistakes, adjust the learning rates, exploration parameters, and neural network architectures to fine-tune the learning process. This can help accelerate learning and improve fusion to better strategies.
- Opponent Modeling:
- My neural network can learn not only from my mistakes but also from the successes of my virtual opponent (my son’s neural network). This process simulates my son’s strategies and adapts to counter them.
- Iterative Improvement:
- Continue playing games against the opponent’s neural network, updating the networks’ parameters, and fine-tuning my strategies based on the outcomes and analysis of each game.
This “Neural Network Duel” setup leverages reinforcement learning concepts and neural network architectures to simulate a learning process similar to how I and my son would improve by playing against each other. In DL it uses many layers of nonlinear processing units for feature extraction and transformation. Over time, the neural networks should adjust their strategies and develop more effective play styles.

Conclusion – For any effective machine learning model requirement is only one which is reliable data pipelines. We have seen in the post above that ANNs don’t create or invent any new information or facts. ANN help us make sense of what’s already in front of us hidden in our data. Deep Learning, in short, is going much beyond machine learning and its algorithms that are either supervised or unsupervised. ANN’s structure is what enables artificial intelligence, machine learning and supercomputing to flourish. Neural networks are powered by language translation, face recognition, picture captioning, text summarization and a lot more.
—
Books Referred & Other material referred
- Open Internet reading and research work about Neural Network Algorithms
- AILabPage (group of self-taught engineers) members hands-on lab work.
Points to Note
When to use artificial neural networks as opposed to traditional machine learning algorithms is a complex one to answer. It entirely depends upon the problem at hand to solve. One needs to be patient and experienced enough to have the correct answer. All credits if any remain on the original contributor only. The next upcoming post will talk about Recurrent Neural Networks in detail.
Feedback & Further Question
Do you need more details or have any questions on topics such as technology (including conventional architecture, machine learning, and deep learning), advanced data analysis (such as data science or big data), blockchain, theoretical physics, or photography? Please feel free to ask your question either by leaving a comment or by sending us an via email. I will do my utmost to offer a response that meets your needs and expectations.
============================ About the Author =======================
Read about Author at : About Me
Thank you all, for spending your time reading this post. Please share your opinion / comments / critics / agreements or disagreement. Remark for more details about posts, subjects and relevance please read the disclaimer.
FacebookPage ContactMe Twitter
====================================================================

[…] after the human mind, the Artificial Neural Network acts as an unlimited labyrinth of neurons or just, nodes shifting data to and from one […]
[…] neural networks as oppose to traditional machine learning algorithms is a complex one to answer. Neural network architecture and its algorithms may look different to many people but in the end, there is nothing wrong to have them in your tool […]
[…] How Neural Network Algorithms Works : An Overview | Vinod Sharma’s Blog […]
[…] networks as oppose to traditional machine learning algorithms is a complex one to answer. Neural network architecture and its algorithms may look different to many people but in the end, there is nothing wrong to have them in your tool […]
[…] oppose to traditional machine learning algorithms is a complex one to answer. Neural network architecture and its algorithms may look different to many people but in the end, there is nothing wrong to have them in your tool […]
[…] Real-Time AI) as opposed to traditional machine learning algorithms is a complex one to answer. Neural network architecture and its algorithms may look different to many people but in the end, there is nothing wrong to have them in your tool […]
[…] How Neural Network Algorithms Works: An Overview […]
[…] How Neural Network Algorithms Works: An Overview […]
[…] networks as oppose to traditional machine learning algorithms is a complex one to answer. Neural network architecture and its algorithms may look different to many people but in the end, there is nothing wrong to have them in your tool […]
[…] How Neural Network Algorithms Works: An Overview […]
[…] How Neural Network Algorithms Works: An Overview […]
[…] How Neural Network Algorithms Works: An Overview […]
[…] Neural Network Architectures – Different types of problems can be solved using different types of deep learning structures called neural network architectures. Some types of computer programs help to analyze images, sequence data and generate new content. These programs are called Convolutional neural networks (CNNs), Recurrent neural networks (RNNs), and Generative adversarial networks (GANs). These networks are made to use the different types of information and ways of learning. […]
[…] How Neural Network Algorithms Works: An Overview […]